Using Clojure to Implement a Web Service Server
Introduction
I was asked to create a proof-of-concept for storing and analyzing clickstream events. The events would be stored in a data lake using AWS S3 and AWS Glue, and for testing the data lake I needed a clickstream generator that simulates customers browsing product groups and products in a hypothetical web store. The picture below shows the AWS infrastructure of the POC.
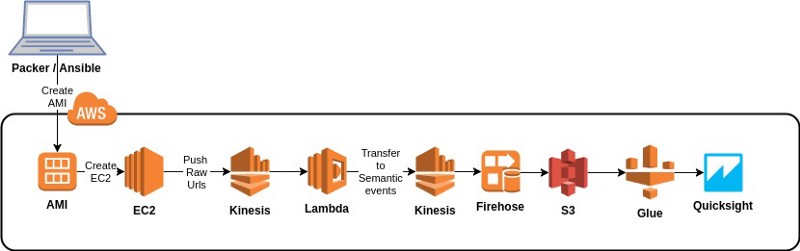
Proof-of-concept of a S3 based Data lake for Clickstream events.
So, this would be a good reason to refresh my Clojure programming skills (see my earlier Clojure related blog post: Clojure Impressions Round Two.
The implementation of the Clickstream Web service server is in my github account: https://github.com/karimarttila/clojure/tree/master/clickstream-generator . The link shows the README.md which explains most of the technicalities, so I’m not going to explain the same stuff here. Instead, I’ll write here some experiences implementing a Web service server using Clojure, how to develop a Clojure application and how to integrate the Clojure application with AWS.
Clojure REPL Rocks
I have been using Tensorflow lately in my Machine learning exercises, and therefore used quite a bit the Python REPL (both with PyCharm and command line). Python REPL is good (if you have used languages like Java which provide no REPL at all — except Java 9 introduced some REPL which I haven’t tried yet). But every time I use the Python REPL I just miss the power and easiness of the Clojure REPL, especially when using it with Cursive. And using Cursive is even more enjoyable if you assign good hot keys for it. Some of my own favorite Cursive hot keys are:
-
(In editor)=> Switch REPL namespace to current file (which is in editor when the command is given). -
(In editor)=> Load current namespace to REPL. -
<Å> (In editor)=> Send S-expression to REPL input. -
=> Focus to Editor last edit (this is a standard functionality in Cursive). -
=> Focus to REPL output. -
=> Focus to REPL input. -
<I/K> (In REPL) => Browse REPL history. -
(In REPL) => Send REPL input to REPL to be evaluated. -
<J/L> (In editor) => Switch tabs in editor. -
- (In editor) => Switch to next editor window (as in Emacs). -
<7> => (In editor) Reformat current file. -
<8> => (In editor) Run the test case which the cursor points currently. -
<9> => (In editor) Run all test cases in the file. The following picture shows an example how to use the IntelliJ IDEA / Cursive REPL.
IntelliJ IDEA with Cursive.
So, in the editor window I have entered the hot key
Clojure Testing
The example above was created for an internal throw-away POC so I didn’t implement that many test cases for it. There is one test, however. The test verifies that the product group probabilities work as expected within a given delta. Test cases are pretty easy to create using Clojure. Clojure code is tight and pretty declarative so it is usually very easy to see the purpose of the test code just by looking at it. For tests I have two favorite hot keys:
Web Service Implemented Using Clojure
Starting/stopping the clickstream server is exposed as a web service. I have used two widely used Clojure libraries for the web service functionality:
- Ring which is a Clojure web applications library.
- Compojure which is an excellent routing library for Ring Take a look of the server.clj file which provides the web service server functionality. The web server initializes itself and then goes to stopped state (not sending clickstream events to Kinesis stream). When you want to start the demonstration you send a http command to the web server:
curl http://localhost:3000/start?token=
The server provides simple routing of these urls:
(co-core/defroutes app-routes
(co-core/GET "/info" [] (-get-info))
(co-core/GET "/status" [token] (-get-status token))
(co-core/GET "/start" [token] (-start-click-generator token))
(co-core/GET "/stop" [token] (-stop-click-generator token))
(co-route/resources "/")
(co-route/not-found "Not Found. Use /info for information."))
I use the Clojure async/go functionality to generate the clicks while the web server itself continues to listen commands in the main thread:
(defn -generate-clicks
[]
(log/trace "ENTER -generate-clicks")
(async/go (while (= [@server](http://twitter.com/server "Twitter profile for @server")-state :running)
Clojure and Data Handling
Using Clojure to implement data oriented applications is easy since Clojure is very much data oriented language itself. I don’t miss that much of the Java boilerplate (classes, setters/getters etc.) to implement simple stuff. With Clojure you don’t need any of that boilerplate but you can focus on the application data and logic itself.
Clojure and AWS Integration
There is an excellent AWS API library for Clojure: Amazonica. There is an example in the streamer.clj file how to use it:
(defn -put-record-to-kinesis
"Puts a url event to kinesis stream."
[url]
(let [kinesis-stream-name (cg-prop/get-str-value "url-kinesis-stream-name")
data {:url url}]
(amazonica-kinesis/put-record kinesis-stream-name
data
(str (java.util.UUID/randomUUID)))))
If you are interested to use Clojure with AWS you should explore Amazonica — there are API functions for all major AWS services like Kinesis, EC2, S3, Lambda, SNS, SQS… And if you don’t find a Clojure API for some specific AWS service or functionality you can always use the Java AWS SDK since Clojure is a JVM hosted language and seamlessly integrates with Java.
Deployment
There are two basic ways to create a deployment unit for this kind of web server in an AWS environment: AWS AMI and Docker container. AWS Lambda is not an option since the web server is a stateful entity (knows whether it is in a stopped or running state). For the POC I wanted minimal hassle so I used Packer and Ansible to create a simple AMI which could be then deployed as part of the AWS POC infra. I have already covered how to create AWS AMIs and Docker containers in other blog posts, e.g. How to Create EC2 Images in AWS?, How to Create Docker Containers in AWS? and AWS Batch and Docker Containers.
Conclusions
Using Clojure to implement all kind of software components is really a joy. Using Clojure REPL makes the software development an exciting exploratory journey — no more long compile-build-deploy-test cycles but you can test small Clojure functions in isolation using the REPL. You can then package your Clojure applications as an AWS AMI or a Docker image to be used in an AWS environment.