AWS Batch Revisited
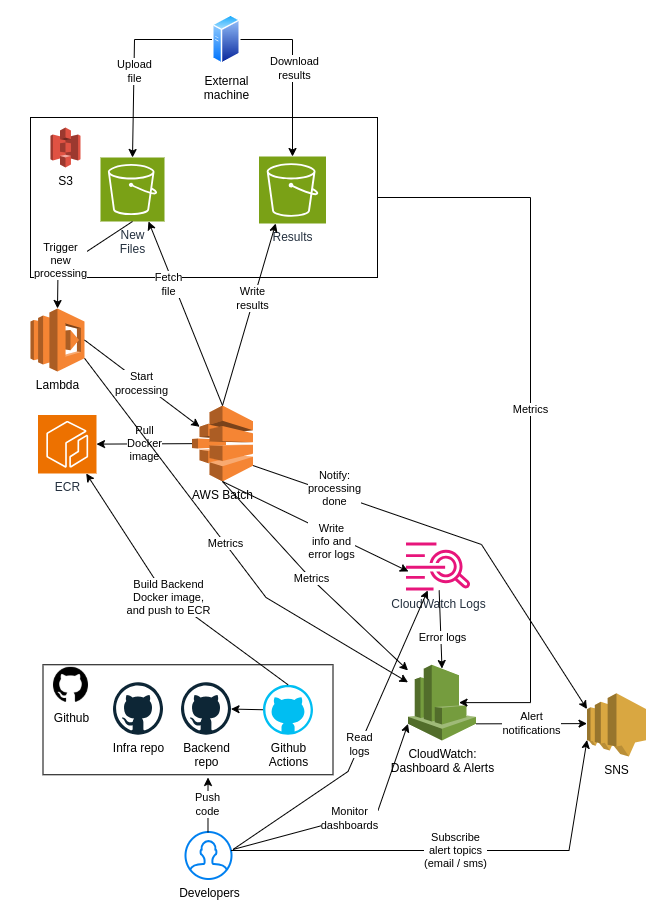
A typical AWS Batch architecture.
Introduction
Almost ten years ago I was working in another corporation and we built a system for one customer using AWS Batch. I have documented that story in this blog post: AWS Batch and Docker Containers.
Now, after all these years, I got a similar use-case in my current project: batch processing in AWS infrastructure. A chance to implement the batch processing again using AWS Batch service.
What Is AWS Batch?
AWS Batch service is a fully managed service that you can use to run various workloads in the AWS infrastructure. You don’t have to worry about the computing environment (to set up a complex orchestration e.g. using EKS or ECS) - you can configure AWS Batch to use Fargate which provides a serverless computing environment for your workloads. AWS Batch offers queues, job definitions and job management as part of the solution.
If you need more complex orchestration, you should consider AWS Step Functions or Amazon Managed Workflows for Apache Airflow (MWAA). I have written a couple of articles regarding these services:
The AWS Batch Use Case
The diagram above depicts a typical AWS Batch use case. In this scenario some external entity uploads some file to “New files” S3 bucket. The S3 bucket is configured to trigger Lambda when a new object is stored into the S3 bucket. Lambda then triggers an AWS Batch job. We need Lambda since you cannot configure S3 directly to trigger an AWS Batch job.
When AWS Batch starts it pulls the Docker image from ECR, and starts the Docker container. The application in the docker container then fetches the uploaded file and starts processing it. After the processing is done, the application writes results to the “Results” S3 bucket and publishes a notification to SNS to notify various stakeholders regarding a new successful processing.
AWS resources also publish metrics to CloudWatch. You can also publish custom metrics to CloudWatch. And you should, since for some reason AWS Batch does not publish metrics regarding successful and failed jobs. See chapter “Custom Metrics” for more information.
If there are errors, you can configure various alerts and alert notifications to SNS for developers. You can also create a custom CloudWatch dashboard for developers to monitor the most important metrics of your infrastructure. Maybe I write another blog post regarding the custom CloudWatch dashboard later on.
Terraform Code
I created the AWS infrastructure solution using Terraform. I have used Terraform almost ten years now and I am pretty experienced Terraform user. Example regarding the AWS Batch compute environment and queue implemented using Terraform hcl:
resource "aws_batch_compute_environment" "compute_environment" {
name = "${local.res_prefix}-${local.module_name}-compute-env"
compute_resources {
type = var.compute_env_compute_type
max_vcpus = var.compute_env_max_vcpus
security_group_ids = [aws_security_group.batch_sg.id]
subnets = var.vpc_landing_private_subnets
}
service_role = aws_iam_role.batch_service_role.arn
type = var.compute_env_service_type
depends_on = [aws_iam_role.batch_service_role]
tags = merge(local.default_tags, {
Name = "${local.res_prefix}-${local.module_name}-compute-env"
})
}
resource "aws_batch_job_queue" "job_queue" {
name = "${local.res_prefix}-${local.module_name}-job-queue"
state = var.job_queue_state
priority = var.job_queue_priority
compute_environment_order {
order = 1
compute_environment = aws_batch_compute_environment.compute_environment.arn
}
tags = merge(local.default_tags, {
Name = "${local.res_prefix}-${local.module_name}-job-queue"
})
}
Custom Metrics
In your application you can easily publish metrics to some custom namespace. An example using Python:
def publish_cloudwatch_metric(
metric_name, value=1, namespace=DUMMY_BATCH_NS, dimensions=None
):
try:
metric_data = {
'MetricName': metric_name,
'Value': value,
'Unit': 'Count'
}
if dimensions:
metric_data['Dimensions'] = dimensions
cloudwatch_client.put_metric_data(
Namespace=namespace,
MetricData=[metric_data]
)
# ...
if __name__ == "__main__":
# ...
try:
processing()
# Process succeeded - publish success metric
dimensions = [
{
'Name': 'SomeKey',
'Value': os.environ["SOME_KEY"]
}
]
publish_cloudwatch_metric(
'ProcessingSucceeded', 1, DUMMY_BATCH_NS, dimensions
)
# ...
Conclusions
After all these years AWS Batch is still a good option for simple batch processing in the AWS infrastructure. If you need more complex batch processing, consider using AWS Step Functions.
The writer is working at a major international IT corporation building cloud infrastructures and implementing applications on top of those infrastructures.
Kari Marttila
Kari Marttila’s Home Page in LinkedIn: https://www.linkedin.com/in/karimarttila/