AWS Step Functions - First Impressions
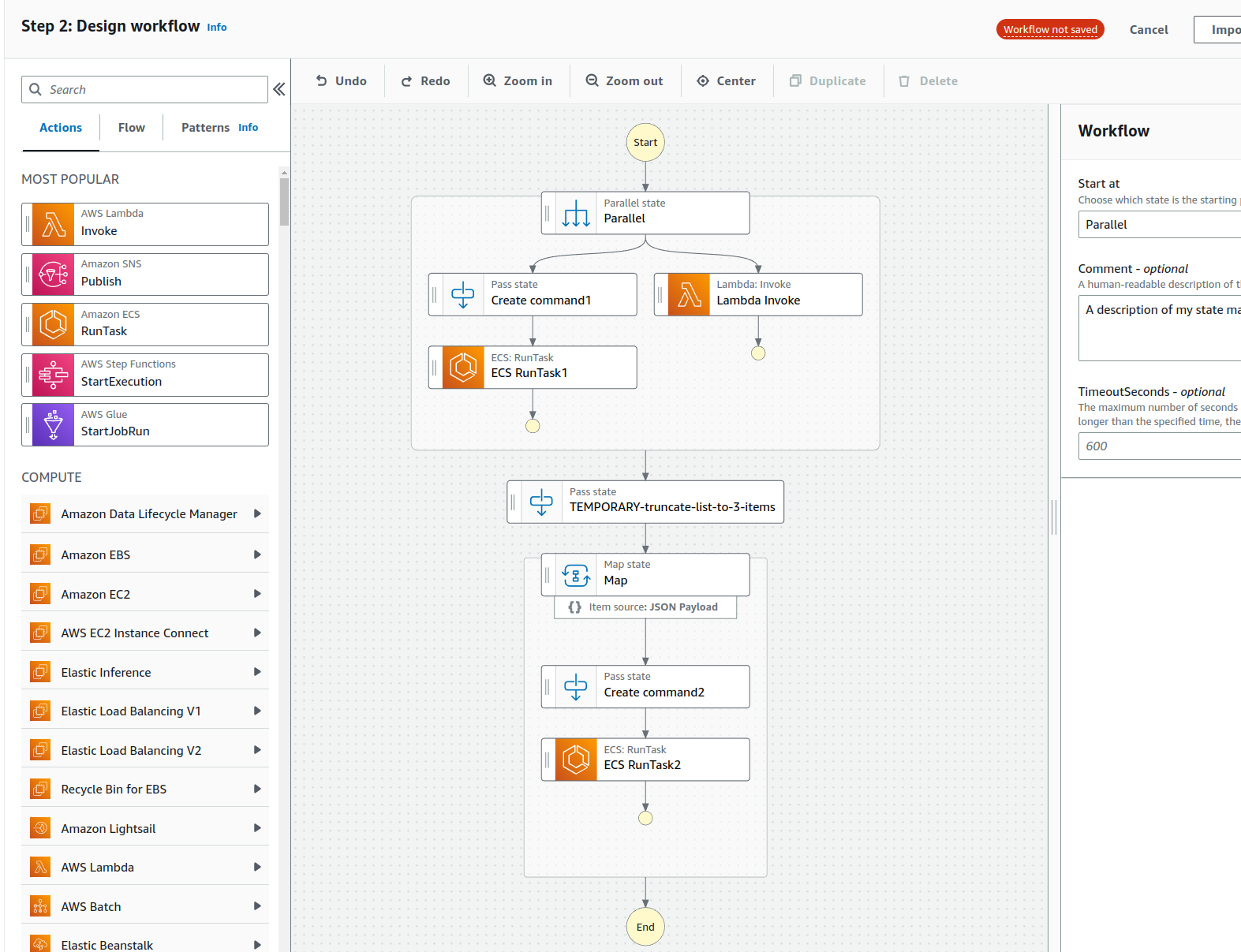
AWS Step Functions Workflow Studio.
Introduction
As I mentioned in my previous blog post, I joined a new interesting project a couple of months ago. In this new project, I was asked to help the domain specialists to implement a long lasting process that comprises a couple of ECS tasks and one lambda, a bit like the demonstration process in the graph above that I created for this blog post.
The domain specialists gave me the SQL query for the lambda and I implemented the rest of the lambda. We agreed with domain specialists regarding the command line parameters of the ECS tasks. While I waited for them to implement the Docker images for the ECS tasks, I implemented dummy versions of the Docker images with the agreed contract - the dummy containers just echo the arguments passed to the container. The reason for implementing the dummy Docker images was to develop the overall process and I didn’t have to wait for the actual Docker images to be ready.
What is AWS Step Functions?
AWS Step Functions is an orchestration service that lets you combine various AWS services as part of your process. The process can comprise Lambdas, Elastic Container Service, and some 200 other AWS services to choose from.
If you have a process which has various tasks, and some of the tasks can be executed in parallel (as the ECS RunTask1 and Lambda in the graph above), some of the tasks are dependent on the results of the previous tasks, and some tasks need to be mapped to some result list values (as the Map step and its ECS RunTask2 in the graph above), then AWS Step Functions is a good choice to implement the process.
With AWS Step Functions you can develop the process using a nice visual workflow modeller (as depicted in the picture above). And once your process is ready, you can export the process definition as a JSON file and use that JSON file to create the process in AWS Step Functions, and automate the infrastructure using e.g. AWS SAM (see my previous blog post: Using AWS Serverless Application Model (SAM) First Impressions).
The Data Flow
You create your process using the off-the-shelf components (pass, parallel, map, choice), and integrate AWS services into the process. The main idea is that you pass JSON object from one step to another, and each step modifies the JSON object in some way (e.g. enriching it with new data, or filtering some data out of it).
Manipulating the JSON Object
Since the JSON object plays such a central role in the process, it is important to understand how to manipulate the JSON object. There is one important hard limit with the JSON object, and Step Functions provide various methods to manipulate the JSON object.
The Hard Limit of the Payload
In paper, this all sounds nice. But in practice, it is far from easy. There are certain peculiarities that you need to take into consideration.
One of the main limits is that you can only pass a JSON object with a maximum size of 256kB - and that is not much. If you have a process that has a lot of data, a best practice is to store the JSON object in S3 bucket and let the next step fetch the JSON object from the S3 bucket.
Another solution is to provide in the JSON object only the data that is needed in the next step. If you have a list of objects, e.g.
{"mylist": [{"id": 1, "name": "Kari", "occupation": "IT specialist", "address": ...},
{"id": 2, "name": "Matti" ...}
...
]
}
… you might be able to fetch the name, occupation, and address fields in the actual step, and just pass a list of ids:
{"mylist": [1, 2, 3, 4, 5, ...]}
However, you may want to use this method only if you are 100% sure that the list of ids will never exceed the 256kB limit. Walk on the safe side of the street and just store the intermediate JSON results in S3.
For more information regarding how to use the Map state: Map state processing modes - use Distributed mode if you have a lot of data.
Input and Output Manipulations
The Step Functions provide Input and Output Processing in Step Functions. You can filter out the input JSON object and pass only the fields that are needed in the next step. You can enrich the JSON object with new fields, and do other kind of manipulations with it. Check out the documentation for more details.
Substitutions
You can inject values from your AWS SAM template into the Step functions process definition using substitutions.
Example. You have a SAM IaC automation. In that automation you have a samconfig.toml file which comprises the parameters for each environments you use, e.g. the subnets for your ECS tasks:
"SubnetIds=subnet-xxxxxxxxxxxx,subnet-yyyyyyyyyyy",
Then in your SAM template.yaml file you have the parameter declaration, and a block for Step function parameter substitutions:
SubnetIds:
Type: List<AWS::EC2::Subnet::Id>
Description: List of subnet ids
...
MyStepFunctionsProcess:
Type: AWS::Serverless::StateMachine
Properties:
DefinitionSubstitutions:
ECSClusterArn: !Ref ECSClusterArn
ECSSubnetIds: !Join [ ",", !Ref SubnetIds ]
...
Here comes the tricky part. You have converted the comma separated list of subnets first as an array (since you need it as an array elsewhere in the template.yaml file), and now you convert the array as comma separated string, and inject it using Step functions substitution to your process definition json file.
But in your Step functions process definition json file you need it as an array once again. You cannot do it with intrinsic function right away (see next chapter) since you need the substitution to be done first. So, do the substitution in one step, and then convert the string to array in the next actual ECS step:
"substitute-ecs-parameters-pass": {
"Type": "Pass",
"Next": "ecs-task",
"Parameters": {
"subnets": "${ECSSubnetIds}",
...
"ecs-task": {
"Type": "Task",
"Resource": "arn:aws:states:::ecs:runTask.sync",
"Parameters": {
"LaunchType": "FARGATE",
"Cluster": "${ECSClusterArn}",
"TaskDefinition": "${MyECSTaskDefinitionArn}",
"NetworkConfiguration": {
"AwsvpcConfiguration": {
"Subnets.$": "States.StringSplit($.subnets, ',')",
"SecurityGroups.$": "States.StringSplit($.securityGroups, ',')",
"AssignPublicIp": "ENABLED"
}
},
...
A bit of conversions, but it works.
Intrinsic Functions
You can also use Intrinsic functions to manipulate the JSON object. For example, you can use States.Format to format the JSON object as a string, and States.Array to create an array of objects from the JSON object. Once again, check out the documentation for more details. See example of using "Subnets.$": "States.StringSplit($.subnets, ',')", in the previous chapter.
Data Flow Simulator
Since it is a bit awkward to use these crudimentary JSON manipulation methods, AWS provides a Data Flow Simulator to the JSON conversions, and you don’t have to test the manipulation results running your Step Functions process. I strongly recommend to develop your process using the Step Functions Workflow Studio and Data Flow Simulator, since it is really time-consuming to test your process by running it in AWS for every little JSON manipulation change.
The Context
The context tells you e.g. the name of the process, execution id, timestamp, and the JSON object that triggered the process. So, you don’t need to try to manipulate the JSON object that is passed from one step to another always to comrise the initial data - you can always fetch those parameters from the context in any step.
Some Tricks for Development
I already told you the most important trick: use the Step Functions Workflow Studio and Data Flow Simulator and save a lot of time. Try your JSON manipulations in the Data Flow Simulator and only when you are sure that the JSON manipulations work as expected, add the manipulation into your process definition and test it by running your process in AWS.
Use the AWS CLI to start execution of your Step Functions process. For example:
aws-vault exec MY-AWS-PROFILE --no-session -- aws stepfunctions start-execution --state-machine-arn arn:aws:states:eu-west-1:999999999999:stateMachine:kari-testing-step-functions --input "{\"value1\" : \"this-is-value-1\", \"my_ids\": [1 2 3]}"
… and save time by not using the AWS Console to do that and copy-paste the JSON input into the AWS Console every time.
Use temporary development steps e.g. to examine the results, the context, or just truncate the long list of ids from the previous step to some more manageable list for development purposes (if your next step spins an ECS task for each id). Name your temporary steps so that you can easily find them and remove them later (see the graph above: TEMPORARY-truncate-list-to-3-items).
Create commands in the previous step. The diagram above has a “Create command” step before the ECS steps. When implementing the Step Functions I realized that it was really painful to manipulate the ContainerOverrides parameter in the ECS step. It was alot easier to manipulate the command that is injected to the container in the previous step, like:
"command.$": "States.Array(States.Format('{}', $), $$.Execution.Input.someValue, '--some_list', States.Format('{}', $$.Execution.Input.some_list))"
and then inject this command in the ECS step:
"ContainerOverrides": [
{
"Name": "kari-test-container",
"Command.$": "$.command"
}
When Not to Use Step Functions
Step Functions is an excellent tool for describing and implementing a long-lasting complex process. The other side of the coin is that Step Function has a steep learning curve, and manipulating the JSON object between steps can at times be quite awkward. If you have simpler processes, there are other options. For example:
- Just use AWS Lambda. If you have a simple process that can be implemented using a single AWS Lambda function, just use AWS Lambda.
- SQS + AWS Lambda/ECS. You can buffer certain events into the SQS and let Lambda or ECS process the events.
- AWS Batch. If you have a lot of data to process, you can use AWS Batch to process the data in parallel.
- AWS DynamoDB. You can use DynamoDB to store the state of the process and let AWS Lambda or ECS process the data.
- Use your imagination and combine the above and other AWS services to implement your process.
Conclusions
AWS Step Functions is an excellent tool. But remember to allocate enough time to learn it and develop your first process, since the learning curve is rather steep. Save Step Functions for complex processes and use lighter methods for simpler processes.
The writer is working at a major international IT corporation building cloud infrastructures and implementing applications on top of those infrastructures.
Kari Marttila
Kari Marttila’s Home Page in LinkedIn: https://www.linkedin.com/in/karimarttila/