Creating Azure Scale Set with Custom Linux VM Image
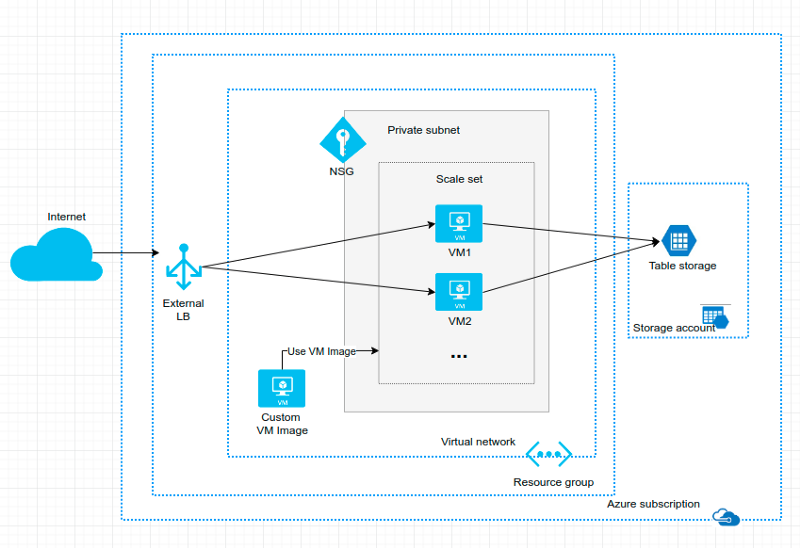
The first version of the Simple Server Azure scale set infrastructure.
Introduction
This is the second part of the Azure Custom Linux VM Image and Scale Set related blog series that I initially thought that there will be only two parts. But then I realized that I’m going to use this exercise to study some Azure security and logging as well. So the series will be:
- Creating Azure Custom Linux VM Image — done.
- Creating Azure Scale Set with Custom Linux VM Image — done (this blog post).
- Configuring Azure Scale Set Security (next blog post, I’m going to review infra’s security features: network security groups, implement a bastion host etc.).
- Configuring Azure Scale Set Logging (the final blog post of this series — probably, unless I figure out something else interesting to study using this exercise).
So, in this blog post I continued my Azure Custom Linux VM exercise and implemented an Azure Scale Set in which I use the custom linux VM I implemented in the previous exercise.
You can find the previous custom VM linux code in the packer folder and the Azure scale set infra code in the terraform folder in my Github repository.
Terraform Code
All Terraform code is in the terraform folder.
Environment Specific Part
Once again I created a dev.tf file in which I define the development environment specific parameters of the infrastructure. Let’s see the most interesting part of this file here:
# These values are per environment.
locals {
...
application_port = "3045"
# NOTE: The custom image must have been created by Packer previously.
scaleset_image_name = "karissvmdemo5-vm-image"
scaleset_capacity** = "2"
# Single-node test mode Cloud-init file:
#scaleset_vm_custom_data_file = "/mnt/edata/aw/kari/github/azure/simple-server-vm/packer /cloud-init-set-env-mode-single-node.sh"
# Azure table storage real mode Cloud-init file:
scaleset_vm_custom_data_file = "/mnt/edata/aw/kari/github/azure/simple-server-vm/personal-info/cloud-init-set-env-mode-azure-table-storage.sh"
}
# Here we inject our values to the environment definition module which creates all actual resources.
module "env-def" {
source = "../../modules/env-def"
#...
scaleset_image_name = "${local.scaleset_image_name}"
application_port = "${local.application_port}"
scaleset_capacity = "${local.scaleset_capacity}"
scaleset_vm_custom_data_file = "${local.scaleset_vm_custom_data_file}"
}
I’ll describe that configuration soon.
High Level Infra
Then we introduce the high level infra — defined in the env-def.tf file.
Main resource group for the demonstration
module "main-resource-group" {
source = "../resource-group"
prefix = "${var.prefix}"
env = "${var.env}"
...
}
module "vnet" {
...module "table_storage_account" {
...module "storage_tables" {
...module "scale-set" {
...
scaleset_image_name = "${var.scaleset_image_name}"
subnet_id = "${module.vnet.private_scaleset_subnet_id}"
vm_ssh_public_key_file = "${var.vm_ssh_public_key_file}"
scaleset_capacity = "${var.scaleset_capacity}"
scaleset_vm_custom_data_file = "${var.scaleset_vm_custom_data_file}"
}
I hope you noticed that we get the scaleset_image_name, scaleset_capacity and scaleset_vm_custom_data_file as parameters from the dev.tf — i.e. the development environment definition to this high level infrastructure definition and we then pass those values to the scale-set.tf module.
Scale Set
The Azure Scale set is a mechanism that provides elasticity for a virtual machine based computing model. You can easily scale out and in the VMs — just change the scaleset_capacity parameter value in your environment terraform code and apply changes to the environment. (By the way, you should never touch the infrastructure e.g. using Portal if your infra is managed using some infra as code tool like Terraform — always keep all changes in the infrastructure code to keep the environments consistent, read more about that e.g. in my previous blog post How to Create and Manage Resources in Amazon Web Services Infrastructure? which is written in the AWS side but the cloud infrastructure best practices apply the same way in the Azure side.)
So, below we see the actual “scaleset” resource in the “scale-set” module, you can see how we are finally using those parameters with this cloud resource:
data "azurerm_image" "scaleset_image_reference" {
name = "${var.scaleset_image_name}"
resource_group_name = "${var.rg_name}"
}
resource "azurerm_virtual_machine_scale_set" "scaleset" {
...
sku {
...
capacity = "${var.scaleset_capacity}"
}
storage_profile_image_reference {
id="${data.azurerm_image.scaleset_image_reference.id}"
}
...
The Idea
So, what’s the purpose of this? This way we can create as many environments as we want and those environments are as exact copies of each other as we want — and using these parameters we can make controlled variations to the environments. Let’s have an example. We have been developing a web store system — the requirement of this project is that the application binary needs to be baked into a Linux image and should be running elastically in a scale set — we are going to double the computing capacity (virtual machines) before Christmas sale. Ok, the development has been going on for a few months and the first version of the web store application and the the Azure infrastructure have been ready for some time and the system is running smoothly in production. While the web store Linux image v. 1.0 is running in production (e.g. in our terraform prod environment), the QA team is testing the next version of the web store 1.1 which is deployed in to the QA environment (e.g. in our terraform qa environment with image 1.1). At the same time our development team is implementing the web store version 1.2 (in our terraform dev environment). The team’s continuous integration (CI) server gets triggered every time someone commits application code to team’s git repository. The CI server builds the application, runs all unit and integration tests and if everything is fine this far the CI server starts to the automatic new image (v. 1.2.z) building process (see folder packer — this could be automated quite easily). When the new image is ready the CI server deploys the image to the development environment and runs all end-to-end tests in that environment.
So, let’s go back to those parameters. Using parameter scaleset_image_name we can inject a specific image to be used in a specific environment (as in the example: image 1.0 in production, image 1.1 in QA and image 1.2 in development). Using parameter scaleset_capacity we can choose in how detail we want to simulate the actual production environment. Perhaps in the development environment we run only a couple of VMs to cut some expenses, but in QA and performance testing environments we want to use the same number of VMs as is running in the production to get more assurance that our testing results apply to production environment as well.
Testing the Azure Scale Set with a Custom Linux VM
All right. We have created our custom Linux VM (my Clojure Simple Server baked into the image with the openJDK runtime) and we have the Azure cloud infrastructure as code and we have deployed the cloud infra to an Azure subscription. Then let’s test the application in the real cloud infra. To make a long story short let’s just say that the image worked in the scale set just fine when running the app with the single-node test mode (simulating DB inside the app). But when I tried to run the app with the real azure-table-storage mode hitting the real DB in an Azure Storage account (Storage no-sql Tables) I had, well some difficulties. I finally figured out that the problem was actually pretty simple, I had hassled some environment variables. I created a new cloud-init file for this mode and then everything worked fine. If you want to read the longer story about my hardship I documented the longer story in the README.md file.
Other Stuff… and the Story Continues in My Next Blog Post
If you read the terraform modules folder you can see that there is other stuff as well: storage-account, storage-tables, vnet and so on. I’m using this exercise to build a bit more real production like environment that we can use e.g. in cloud sales meetings to demonstrate how we are building cloud infra in Tieto using cloud best practices. But I’ll write more about those entities in my next blog posts, so stay tuned!
The writer has two AWS certifications and one Azure certification and is working at the Tieto Corporation in Application Services / Application Development / Public Cloud team designing and implementing cloud native projects. If you are interested to start a new cloud native project in Finland you can contact me by sending me email to my corporate email or contact me via LinkedIn.
Kari Marttila
Kari Marttila’s Home Page in LinkedIn: https://www.linkedin.com/in/karimarttila/