AWS IoT Storage Considerations
First published 2021-09-22 in the Metosin Blog.
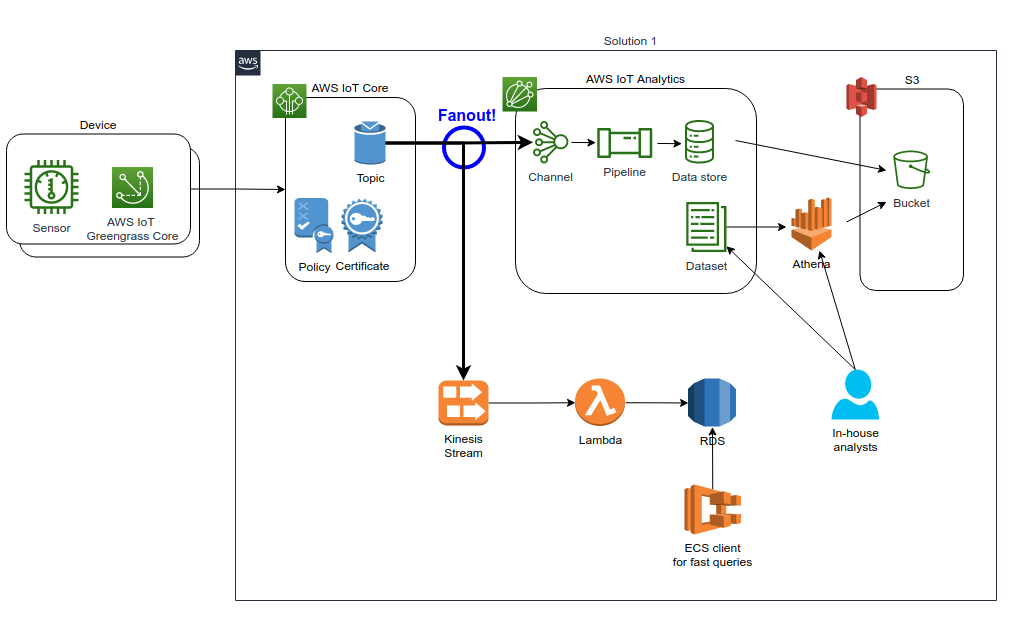
The IoT storage architecture based on AWS IoT Analytics S3 data lake and RDS.
Introduction
In my previous blog post AWS IoT First Reflections, I described my first AWS IoT platform reflections on implementing an AWS IoT platform for one of Metosin’s customers. In this new blog post, I continue this AWS IoT journey considering where to store the IoT metric data.
Fan-out!
In the previous blog post, I explained my experiments with the AWS IoT Analytics service and various pros and cons. The obvious benefit of using AWS IoT Analytics is getting a managed service as a turnkey solution. One disadvantage is the storage model, S3 based data lake, which is great for in-house analytics but might not be the best solution if you e.g., need fast queries based on certain IoT metric dimensions. A real relational database with indexing might be a better option in this case.
Why not have both worlds? Let’s fan-out! The diagram at the beginning of this article depicts the idea of fanning-out to two different data storages: S3 based data lake (AWS IoT Analytics) and traditional RDS - relational database as a service.
I already explained the IoT device → AWS IoT Core Topic → AWS IoT Analytics Channel/Pipeline/Data-storage → S3 path in my previous blog post. You can create various AWS IoT Topic Rules and use those rules to integrate the producer (the Topic) to some consumer. In the diagram, there is a fan-out circle which consists of two rules:
- Send messages to an AWS IoT Analytics Channel.
- Send messages to a Kinesis Data Stream.
I already explained the upper part of the diagram in my previous blog post. Let’s spend some time with the lower part.
So, we fan-out the messages also to a Kinesis Data Stream. I could have skipped the Kinesis part from the architecture since AWS IoT Core Topic also supports Lambda as an integration point. But I wanted to add the Kinesis Data Stream first so that we have an asynchronous buffer for the messages for some future use that we still don’t know. E.g., you can add Kinesis Data Analytics to analyze the streaming data in real-time, perhaps trigger a notification for certain messages, etc.
After the Kinesis Data Stream, we have a Lambda function in the architecture diagram. The Lambda function listens to the Kinesis data stream and gets chunks of records as events. The Lambda function then connects to the RDS and inserts the records into the RDS. I also experimented using Amazon RDS Proxy to pool the database connections but let’s write another blog post about it in the future.
Two Storages - Two Use Cases
Now we have the IoT metrics data in two data storages. (Actually, in three - the AWS IoT Analytics stores both the raw events and the processed events - processing happens in the AWS IoT Analytics Pipeline.) The IoT platform we have built serves two use cases:
- Backend system implemented using ECS. The backend queries recent messages from the RDS. It is easy to implement some retention policy so that the RDS comprises, e.g. only the IoT messages regarding the last 24 hours, etc. (this keeps queries fast since there is not that much data to be indexed).
- Human in-house analysts. The analysts may query the S3 data lake, which comprises every message any IoT device has ever sent to the system - the storage space of the S3 data lake is, for practical purposes, well infinite. S3 also provides very cost-efficient storage for this kind of historical data. For constant analytical purposes, we can implement a certain number of AWS IoT Analytics Datasets (and to be run on a regular basis, e.g. at night, so that analysts have the latest result when they start working in the morning). AWS IoT Analytics provides two data storage models: service managed and customer managed. In a customer managed storage, you provide the S3 bucket yourself. If you use a customer managed bucket, you have all the data in your S3 bucket - a more experienced analyst can use Athena to make complex analytical queries for all historical IoT metrics data.
Conclusions
We started our IoT journey with a simple solution using two services - AWS IoT Core and AWS IoT Analytics and, using those services, building a pipeline to store IoT metrics data to the S3 data lake. Now we have enhanced the original architectural solution by fanning-out the data to another pipeline that can provide real-time analytics and fast queries using a relational database. This is truly the power of AWS - there are a lot of various building blocks that you can use to implement a complex system that can serve different use cases.
The writer is working at Metosin using Clojure in cloud projects. If you are interested to start a cloud or Clojure project in Finland or you are interested getting cloud or Clojure training in Finland you can contact me by sending an email to my Metosin email address or contact me via LinkedIn.
Kari Marttila
Kari Marttila’s Home Page in LinkedIn: https://www.linkedin.com/in/karimarttila/