DevOps Success Factors
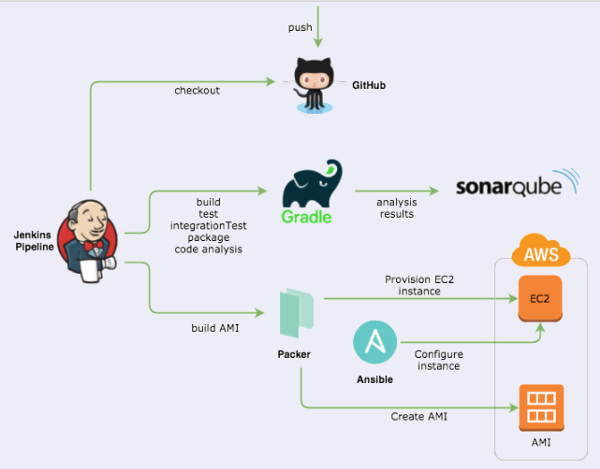
Automating Build Pipeline.
Introduction
We just finished one system that we developed and deployed to AWS infra using certain DevOps practices. The project was a real success: we created AWS infra from scratch (only VPC was provided) and developed the system (2 rest applications and 4 integration applications) in about 5 months with 1 project manager and 3 developers.
After the project we had a short retrospective workshop with the customer to identify the success factors why the project was so successful, so that the customer could use these success factors in their future projects. We list here some generic observations of the identified success factors. The factors are grouped into the following categories: Architecture, Automation, and Methodology, People and Culture.
Architecture
We didn’t have time to invent the wheel so we embraced AWS as much as possible with the strategy: Use AWS services as building blocks to implement your enterprise system which we have described in our first AWS article. AWS provides all aspects of enterprise system infrastructure as services (network, servers, database, queues, notifications, storage, logs, alarms…). We used these services as much as possible and glued various services together to implement a complex enterprise system which would have taken much longer to implement gathering pieces here and there and do more tailoring. All AWS services integrate to each other extremely well and this saved a lot of time in the project.
Automation
With a tight schedule you don’t have time to do things twice — so, you should automate absolutely everything. We automated e.g.
- Build pipeline. We used Jenkins Pipeline (see main picture in the beginning) to orchestrate everything. When a new commit appeared in Git this triggered the Jenkins Pipeline; which builds the system, runs tests (unit tests + integration tests), runs static analysis and sends results to Sonar, and then starts building the AMI (Amazon Machine Image).
- Images. We used Packer and Ansible to create the AMI which was then automatically deployed to dev environment for acceptance tests. We used “Phoenix server strategy” — all server infra, application and configuration was done to the image and only some environment related information was delivered to the AMI when running in AWS. If there was a need to do any other configuration, we just created a new image. AWS supports this strategy well with AWS account based AMI repository.
- Tests. We automated all aspects of testing: unit tests, integration tests and acceptance tests. We used Junit framework with excellent Spring Boot testing framework, and for acceptance test automation we used Robot Framework. Code coverage was very good, in some apps even more than 90%. Good code coverage and automation provided good regression test confidence to support agile work and continuous refactoring for better code structure.
- Resource management. We used strategy Infrastructure as Code regarding AWS resources — all AWS resources and configurations were managed by Terraform code which was versioned in Git (see more detailed description of the strategy in our second AWS article How to Create and Manage Resources in Amazon Web Services Infrastructure?). This strategy made continuous refactoring regarding the AWS infra possible, and also made the various environments (development, testing environments, performance testing environment and production environment) copies of each other — the various types used in different environments were parameterized in Terraform code (e.g. RDS / EC2 instance types).
- Monitoring. All aspects of the system were monitored, and all alarms were configured and managed in Terraform scripts. The monitoring was especially important since after 4 months of hectic implementation we shipped the system into production and the team members monitored the production using our own monitoring tools for the months to come (real DevOps!). All applications send application logs to Cloudwatch. All EC2 instances, queues, S3 buckets, RDS etc. have various alarm metrics which are monitored. If alarms get triggered Cloudwatch sends notifications to SNS topics, which developers subscribed to receive email / SMS alarms. Maybe because of very good automation practices and comprehensive monitoring we could react proactively to various situations so that in production this far there have been zero incidents — the customer was very content regarding the system in production.
Methodology, People and Culture

Successful DevOps team: (left to right) Ville Kuusela (PM), Timo Tapanainen, Kari Marttila and Antti Varjoinen (standing). Our office dog Ulpu visited Tieto CEM office that day.
- Cross-functional team. We had a very small team: 1 project manager and 3 developers. Everyone was doing everything: architecture design, requirement analysis, AWS infra implementation, application development and testing etc. All team members were senior level developers/architects using battle tested frameworks (e.g. Spring Boot).
- Fluent communication. The first month we spent in customer premises collaborating with the customer and gathering basic requirements to start the actual work. The rest of the project all team members sat in a war room dedicated for the project.
- Low ceremony. Ceremony was very low (ceremony meaning how much bureaucratic processes and hassle there is in a software project). There was less bureaucracy and paperwork, and more real implementation work. E.g. we used the war room wall for quick design drawing various ideas quickly to the wall and then implemented it in code.
- A lot of fun. It was a lot of fun to work together. Co-operation with the customer was agile and easy. All team members appreciated the great learning experience we had in the project. Therefore the work morale was high and productive.
Both writers are AWS Certified Solutions Architects Associate, architecting and implementing AWS projects in Tieto CEM Finland. If you are interested about starting a new AWS project in Finland, you can contact us with firstname.lastname at tieto.com.
Kari Marttila & Timo Tapanainen
Kari Marttila’s Home Page in LinkedIn: https://www.linkedin.com/in/karimarttila/
Timo Tapanainen’s Home Page in LinkedIn: https://www.linkedin.com/in/timo-tapanainen/