Deploying Kubernetes Configuration to AWS EKS
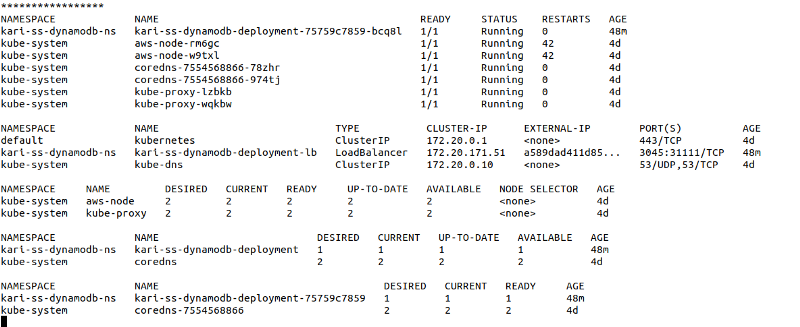
The Simple Server DynamoDB AWS EKS Kubernetes Deployment Listing.
Introduction
This blog post describes the second part of my AWS Kubernetes Services (EKS) studies. In the first part Creating AWS Elastic Container Service for Kubernetes (EKS) the Right Way I created a Terraform configuration for the project infra for the AWS cloud: EKS (the Kubernetes service itself), ECR (AWS Container registry to host the Docker images) and other related cloud infra I needed for the demo application.
In this second part I describe how I created the Kubernetes deployment configuration for my Simple Server so that I’m able to use the same Kubernetes configuration to deploy both the single-node and DynamoDB versions to the AWS EKS Kubernetes cluster.
You can find the project in my Github account.
Tuning the AWS Role Policy
As I mentioned in the previous blog post this time I did test the Kubernetes deployment with the single-node version before I published the blog post. But I left the real DynamoDB version deployment as an exercise for this current blog post. And once again there was some minor tuning.
The development version used the AWS profile found in ~/.aws/credentials but it is not a best practice in AWS to configure production applications in EC2s to use AWS access and secret keys but give EC2 a permission to use the needed services using EC2’s instance profile role (with restricted policies).
First I had to add the missing configuration for allowing DynamoDB access for the EKS worker node instance profile IAM role (so that the application running in a Kubernetes pod running in an EC2 worker node has right to access Dynamodb using the EC2’s instance profile role), see file eks-worker-nodes.tf => resource “aws_iam_role_policy” “eks-worker-node-dynamodb-role-policy”.
Then there was an issue with the amazonica library and my development configuration for using AWS profile — in AWS EKS we are not using the AWS profile but the instance profile. Therefore I had to make a code change so that when the application is running in AWS EKS it is not using the AWS profile but the EC2 instance profile. The development cycle would have been a bit long (make change, create Docker image, tag, push to ECR, deploy to EKS, try whether it is working and if not go back to step 1…). Luckily there is AWS Security Token Service (STS) which provides a feature to assume a certain role and you can test that role running your application locally (in your own workstation) with that role (you get temporary credentials for the role). This is a really nice way to test the IAM role you are going to use in production — checking locally (e.g. in IDE) whether the role has the necessary access rights. In order to assume a role you first have to add your own arn (the user account you are using in AWS) as principal to the assumed role. I didn’t add this to the terraform code since it comprises my user account arn (a bit delicate information). But you can go to AWS Portal / IAM / Roles / kari-sseks-dev-eks-worker-node-iam-role / Trust relationships / Edit trust relationship => add:
{
"Effect": "Allow",
"Principal": { "AWS": "YOUR-USER-ARN-HERE" },
"Action": "sts:AssumeRole"
}
#Then you can get the temporary credentials of assuming "kari-sseks-dev-eks-worker-node-iam-role" role:
AWS_PROFILE=YOUR-AWS-PROFILE aws sts assume-role — role-arn arn:aws:iam::11111111111:role/kari-sseks-dev-eks-worker-node-iam-role — role-session-name local-testing-session — profile "YOUR-AWS-PROFILE"
(The “11111111111111” string is the account id — changed it in this output, a bit delicate information for a blog post).
You get an access key, a secret key and a session key. Use those keys as environmental variables when running the application:
AWS_ACCESS_KEY_ID=
AWS_SECRET_ACCESS_KEY=
AWS_SESSION_TOKEN=
Then you can run the unit tests and see if the application can access all needed AWS resources with the assumed role. I ran the test suite and found out that there actually was one thing I had missed:
dynamodb:Query on resource: arn:aws:dynamodb:eu-west-1:1111111111:table/kari-sseks-dev-product/index/PGIndex (Service: AmazonDynamoDBv2; Status Code: 400; Error Code: AccessDeniedException;
So, the error was actually a good thing because now I verified that:
- I’m using the assumed role — running app with the Kubernetes worker node EC2 instance profile role.
- The Instance profile has rights to query DynamoDB as I configured in the Kubernetes EKS project side.
- But it doesn’t have rights to access the index — that was something I didn’t know when I created the Terraform configuration for that role policy.
So, I added the index into the list of DynamoDB arns that I inject to the eks-worker-nodes module which uses that list for configuring the access for the DynamoDB tables (and index):
output "all_dynamodb_arns_and_indeces_for_access_rights" {
value = ["${module.dynamodb-session.dynamodb_arn}",
"${module.dynamodb-users.dynamodb_arn}",
"${module.dynamodb-product-group.dynamodb_arn}",
"${aws_dynamodb_table.product-dynamodb-instance.arn}",
# NOTE: You have to give access right to the indices as well.
"${aws_dynamodb_table.product-dynamodb-instance.arn}/index/PGIndex"
]
}
So, after fixing the missing role policy (terraform apply…) I ran the test suite again and this time the application worked just fine using the worker node’s IAM Role Policy. So, I knew at this point that at least the role policies are ok and I should be good to go to test the application in the real EKS cluster environment.
Debugging the Environment Variable
So, I deployed the application to AWS EKS cluster using the create-simple-server-deployment.sh script:
AWS_PROFILE=MY-AWS-PROFILE ./create-simple-server-deployment.sh aws-dynamodb aws 11.11.11.11 31111 0.2 dummy-acr 11111111111111 eu-west-1 kari-sseks-dev-eks-ecr
The “11.11.11.11” is the static load balancer ip for the Azure deployment — ignored in AWS deployment, “dummy-acr” is the Azure ACR name — ignored again here, “11111111111111” is the AWS account id, “eu-west-1” is the region I use and “kari-sseks-dev-eks-ecr” is the AWS ECR registry I use.
… and I noticed that the deployment fails. I use SS_ENV environmental variable to tell the application which mode it is supposed to be running (single-node, azure-table-storage, local-dynamodb, dynamodb, aws-dynamodb-eks…). I first forgot that my Clojure build tool Leiningen creates a file .lein-env into which Leiningen dumps the environmental variables found in the Clojure profile.clj file. These environmental variable values override the values found in the environment. Therefore even though I set the environmental variables right in the Kubernetes deployment konfiguration the application read different values in the .lein-env file. Therefore I removed the .lein-env from the Docker image. I deleted the old image from the ECR repository and pushed the new image. And tested the Kubernetes deployment again. And wrong profile again, wtf? I changed the Kubernetes deployment entrypoint so that I could ssh inside the pod and check that the .lein-env file shouldn’t there — but it was. Maybe I somehow had hassled creating the Docker image in the first place? I ssh’d inside the docker image in my workstation that I just used to push the image to ECR — and the file wasn’t there — wtf? It was supposed to be the same Docker image but in my workstation the file wasn’t there (ok) and in ECR the file was there (not ok). I thought that could it be possible that even though I had deleted the old image in ECR there could be some image layers in some ECR cache? I deleted the image again, tagged the image in my workstation with another version number (0.1 -> 0.2), pushed the image to ECR and deployed the Kubernetes configuration using the new tag version 0.2. Everything worked this time. Really odd. I thought a moment for an explanation for this. Either somehow I had hassled the process anyway or ECR really somehow caches some Docker image layers and when you push the image again with the same tag it uses some old layers from the cache (or something like that). Anyway I was happy that after some hours of debugging I finally solved the issue and my poor man’s Robotframework test suite call-all-ip-port.sh happily ran through all test cases.
How to Call the Application Running in AWS EKS?
If you are interested to use this example (a bit of work actually — you have to clone my Clojure, Docker, Kubernetes and AWS repositories, build the Docker image, build the AWS infra using Terraform, tag and push the images to AWS ECR and deploy the Kubernetes deployment configuration to the AWS EKS cluster) I give some final instructions how to call the application running in AWS EKS.
So, I assume that you have successfully created the Docker image, created the AWS infra and deployed the Kubernetes deployment configuration. The application is now running in the AWS EKS cluster. Next you need to get the url for the Kubernetes cluster load balancer. Get it using the kubectl tool:
AWS_PROFILE=YOUR-AWS-PROFILE kubectl get all --all-namespaces
# => Lists the Kubernetes deployment entities (see screenshot at the beginning of this blog post).AWS_PROFILE=YOUR-AWS-PROFILE kubectl describe svc kari-ss-dynamodb-deployment-lb -n kari-ss-dynamodb-ns
# => Gives the description of the Kubernetes configuration load balancer (see below).You get some listing regarding that entity and there is also the LoadBalancer url:
…
LoadBalancer Ingress: XXXXXXXXXXXXXXXXXXXXXXX.elb.eu-west-1.amazonaws.com
…(I replaced the real string with “XXXXXXXXXXXXXXXXXXXXX”).
Use this url to query the application:
curl [http://XXXXXXXXXXXXX.elb.eu-west-1.amazonaws.com:3045/info](http://a589dad411d8511e9b9e00297d7dbc78-287a8ca9a1021bed.elb.eu-west-1.amazonaws.com:3045/info)
# => {"info":"index.html => Info in HTML format"}NOTE: The first time you call the Kubernetes cluster load balancer it might take some 1–3 minutes before it replies. I don't know the reason for this. But the next replies are lightning fast. Maybe AWS somehow configures the load balancer that someone is really using it.
Then use my poor man’s Robot framework script to test all APIs:
./call-all-ip-port.sh [XXXXXXXXXXXXX](http://a589dad411d8511e9b9e00297d7dbc78-287a8ca9a1021bed.elb.eu-west-1.amazonaws.com:3045/info).elb.eu-west-1.amazonaws.com 3045
# => A lot of stuff (returns all values from all APIs it tests)...
# ... and finally the last reply from the last API call:
# {"ret":"ok","pg-id":"2","p-id":"49","product":["49","2","Once Upon a Time in the West","14.4","Leone, Sergio","1968","Italy-USA","Western"]}
By the way, what a coincidence — “Once Upon a Time in the West” is the best western ever made and one of my favorite movies. :-)
Conclusions
The AWS EKS infra is a bit more difficult than creating managed Kubernetes cluster in the Azure side but Kubernetes deployment to both Azure AKS and AWS EKS is pretty much the same (just some minor tagging / annotation differences (see simple-server-deployment-template.yml).
The writer has two AWS certifications and one Azure certification and is working at the Tieto Corporation in Application Services / Application Development / Public Cloud team designing and implementing cloud native projects. If you are interested to start a new cloud native project in Finland you can contact me by sending me email to my corporate email or contact me via LinkedIn.
Kari Marttila
Kari Marttila’s Home Page in LinkedIn: https://www.linkedin.com/in/karimarttila/