AWS Redshift and Creating Test Data Infrastructure
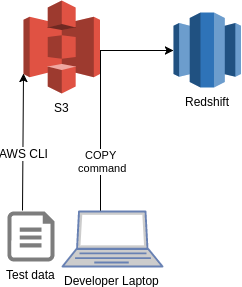
Creating test data in AWS.
Introduction
My project manager, distinguished business consultant Ville, told me a couple of days ago: “Kari, the customer wants us to create a component which fetches certain daily data out of customer’s Big data store, Redshift, and processes the daily data and creates an integration message regarding the results. I want you to start working on it.” Right. I was already waiting to start something new. :-)
Why Test Data and Test Infrastructure?
One of the first things I setup in a new software project is the test data infra. Test data and test infrastructure is fundamental in software development since test data drives your development: the test data with examples is one of the best specifications you can get. And with good test infrastructure it is easy to load and use test data.
There can be several test data infrastructures:
- Unit test data. Unit test data is typically used as part of the development code (in “test” tree). If I work with Java I usually use Spring’s Unit testing framework.
- Integration test data. Integration test data is also used as part of the development code (e.g. in “itest” tree). There are good integration test frameworks e.g. in Spring which help you to populate database tables and test your code against database content.
- Generic test data. You can also use generic test data that customer can provide you e.g. in XML, JSON, CSV, Excel files etc. These are typically real customer data which has certain sensitive data overwritten with some dummy data. The test data can be rather big and therefore it is not convenient to comprise it as part of your code base. This blog post focuses on how to upload this kind of test data into AWS Redshift.
AWS Redshift and Loading Test Data
AWS Redshift can be a bit tricky if you want to load a large amount of test data to it. Let’s share in this blog post some of my experiences during the past couple of days when I created my AWS Redshift test data infrastructure.
Requirements
My requirements were:
- Target database: AWS Redshift.
- Amount of test data: Possibly a lot (since we are dealing with a Big data store :-) ).
- Automation: Pretty good — meaning that I want to be able to truncate the database tables in one command, and load new data sets with another command.
Database
First I had to figure out which database to use. There is one Redshift cluster in each environment. I knew that other developers were using the same dev Redshift cluster for their development work. Basically there were three choices:
- Use the same Redshift cluster and database. Use some tagging with data so that you know what data belongs to you. Upside: No hassle to create new Redshift cluster or database. Downside: Hassle to take the data tagging into consideration when creating test data and doing development.
- Create a dedicated Redshift cluster for your own work. Upside: Total freedom. Downside: Costs.
- Create a new database with the same schema into the existing Redshift cluster. Upside: No extra costs, no hassle with tagging data. Downside: Some terraforming needed. I wanted freedom with my own development (no hassle with other developers) but no extra costs, and therefore chose option #3.
Terraforming
Redshift is based on PostgreSql and there is an excellent COPY command in Redshift and psql client, so using COPY command instead of SQL Insert statements was a natural choice with big data. The problem was that Redshift does not support local files when uploading data to Redshift, the files need to be e.g. in S3. So, I needed to do some AWS infra work — let’s use our favorite Infrastructure as Code tool Terraform!
Terraforming the needed AWS components was a rather simple task: I needed to setup an S3 bucket for the test data and create an IAM role for the COPY command and do some gluing between S3, IAM role and Redshift with AWS policies. It’s always a good best practice to do even small AWS configurations with Infrastructure as code tool since your code serves also as a good documentation e.g. if you want to consult some other developer later on how to do the same trick (instead of doing it in an ad hoc manner using AWS Console).
Truncating the Tables
Truncating tables from old test data was trivial. I just needed two files: one bash file to start the trick and one sql file with actual truncate commands.
Loading new Test Data
Loading new test data had two parts: Uploading new test data to S3 bucket and calling the COPY command.
For uploading the modified test data sets I used AWS CLI, a bash one-liner basically:
AWS_PROFILE=my-dev-profile aws s3 cp $TESTDATA_DIR/ s3://$S3_BUCKET_NAME/$TESTDATA_DIR/ — recursive — exclude "*" — include "*.csv"
The COPY commands were rather simple to create after terraforming of the test data infrastructure:
COPY myschema.mytable FROM 's3://BUCKET/CHANGE_DIRECTORY/testdata.csv' iam_role 'arn:aws:iam::99999999999:role/my-redshift-copycommand-role' DELIMITER '\t' NULL AS '<null>';
… and of course some bashing with sed to create the actual sql file from that template and then feed it to psql.
And that’s it: I have an automated test data infrastructure. I can now easily create local directories for new test data sets and truncate test database and load new data sets to database with a couple of commands. Now I can start the actual development with the help of the test data infrastructure, but let’s write another blog post about that later.