Migrating Big Data in Moving Trains with AWS
Introduction
Let’s say you have created a system in an AWS account in an ad hoc manner (e.g. experimenting and choosing services and gluing them together by hand in AWS Console). Everything seems to be working just fine but one day you realize that you have hundreds of smaller and bigger AWS resources, triggers, groups and flags in your system and maintaining the system becomes a nightmare. Time to do automation! So, you choose some Infrastructure as Code automation tool (e.g. Terraform or CloudFormation) and you create infrastructure code and generate a new infrastructure using your automation tool. Do testing in the new environment and if everything looks good, time to do migration.
But: If your system is a huge big data system receiving a continuous stream of events, it’s a bit like moving load from one train to another while the trains are moving.
Amazon Kinesis
How to build a reliable source for the events to your big data system? If you are using AWS platform Amazon Kinesis is an excellent choice. In the above mentioned link AWS describes Kinesis as “Amazon Kinesis Streams can continuously capture and store terabytes of data per hour from hundreds of thousands of sources such as website clickstreams, financial transactions, social media feeds, IT logs, and location-tracking events.” For migrations there is an excellent feature in Amazon Kinesis: it can buffer all coming events up to maximum 168 hours. So, basically you can just disable your processors to consume events in the Amazon Kinesis streams and the events will stay safely buffered in your streams up to one week.
One way to move load from one moving train to another is to switch your integrations to start using the new environment’s Kinesis streams, but don’t enable consuming the streams yet. Then wait for the current environment to consume the events from the current environment’s streams until they are all processed and/or stored into current environment’s permanent data stores. Now you have 168 hours to do any other migration work (e.g. move stuff of S3 buckets, move databases from the current environment to the new environment, do testing etc.).
Fanout
Every migration specialist prepares himself for the worst to happen: time to do contingency plan!
Let’s visualize a worst case scenario. We have switched integrations to the new environment’s source streams. What if when we start consuming the events from the new environment’s streams we realize all hell breaks loose? Events arrived to broken new environment, events were lost and we cannot roll back to current environment since it lacks the latest data.
Let’s draw a solution with contingency capability.
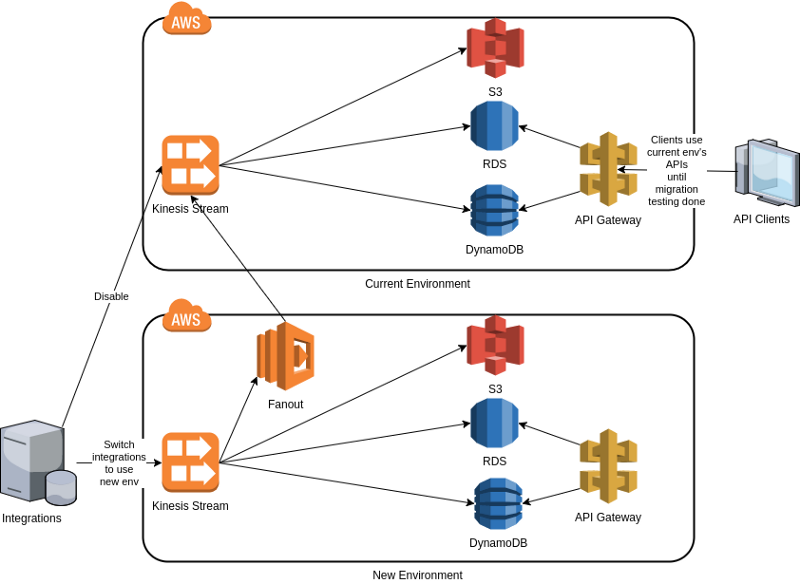
Migrating data in a moving train.
One way to migrate to new environment with the capability to roll back to current environment in big data type system using Kinesis streams and AWS Labs Fanout component. Diagram is conceptual, you could use Redshift instead of RDS, and you need e.g. Lambdas / EC2s between data stores and API Gateways.One solution would be in the current environment to consume the events from the new environment’s streams instead of current environment’s source streams (Kinesis streams have dedicated readers per consumer) . Or replicate the events from the new environment’s source streams to current environment’s source streams — current environment thinks the events are coming from the integrations, business as usual — and actually they are, this time only via replication. But how to do the replication of Kinesis events? Help comes from AWS Labs: Fanout. Fanout is a component from AWS Labs which is pretty easy to configure and is able to read a Kinesis stream and replicate (fan out) the events to another Kinesis stream even if the target stream exists in another AWS account.
Using this kind of event replication you are able to receive the integration events to the current environment and to the new environment simultaneously. Your API clients can safely continue using the current environment’s APIs since the current environment is receiving events just as before migration (but this time just via replication). Now you have all the time in the world to test the new environment, event processing and storing, its APIs etc. After testing you have two choices: 1. New environment is working fine — switch all APIs to use the new environment and decommission the current (old) environment; or 2. New environment is not working quite right — no problem, you can just switch the integrations back to current environment’s streams (directly, not via replication any more), find out the problems in the new environment and try the migration another time.
Special Thanks
Thanks to my friend and distinguished AWS guru Timo Tapanainen for proposing the general idea of the migration using event replication and to use Fanout from AWS Labs to do the actual event replication.
Conclusion
AWS is a great platform for hosting your big data systems. AWS also provides excellent tools for doing migrations even with demanding big data systems which are like moving trains.
The writer is AWS Certified Solutions Architect Associate and AWS Certified Developer Associate, architecting and implementing AWS projects in Tieto CEM Finland. If you are interested about starting a new AWS project in Finland, you can contact me with firstname.lastname at tieto.com.
Kari Marttila
Kari Marttila’s Home Page in LinkedIn: https://www.linkedin.com/in/karimarttila/