Big Data with Amazon Web Services
Introduction
We attended a three day AWS Big Data course last week (given by Luis Herrera — the best IT trainer I have met in 20 years; Luis is not a professional lecturer but a hands-on consultant with a massive amount of practical knowledge about Big Data, AWS and Docker which everyone attending the course could easily see). The course was a pretty good introduction to Big Data services provided by AWS, with a lot of hands-on labs. In this blog post we give a short introduction to AWS Big Data services.
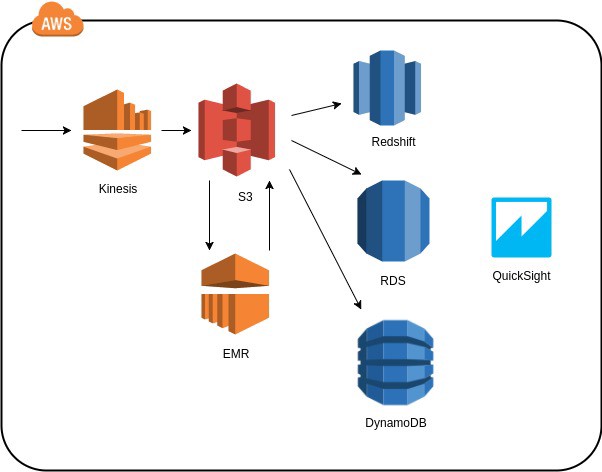
Conceptual diagram related to Big Data streaming, storing, processing and visualization using AWS services.
Regarding the AWS Big Data area Amazon Web Services has once again done excellent job adapting successful OSS tools to the AWS ecosystem: Hadoop wrapped as AWS EMR, AWS Kinesis modeled after Kafka etc. And two of my favorite AWS principles are again beautifully incorporated in AWS Big Data: 1. You can use AWS services as building blocks to implement your Enterprise system — this time you can use AWS Big Data services without the need to implement the Big Data infrastructure yourself, and 2. All AWS services integrate to each other extremely well. The two above mentioned AWS principles also resonate wonderfully together. AWS truly is the one-stop-shop platform where you can get everything you need to build your enterprise system and incrementally let it evolve according to your future needs. We have seen so many wonderful examples how to use these services together that basically your imagination is the limit how you can combine different AWS services to build your enterprise system.
What is Big Data?
According to Wikipedia:
“Big data is a term for data sets that are so large or complex that traditional data processing application software is inadequate to deal with them.”
We have seen this definition to be used rather liberally, e.g. with data sets that could have easily been loaded to our previous generation steam powered laptops. But with layman’s terms you can think of a data set that is so big that it cannot be stored or processed efficiently in traditional relational based systems.
We have divided this blog post into four parts: how to stream Big Data, how to store Big Data, how to process Big Data and how to visualize Big Data using AWS tools.
1. Streaming Big Data using AWS
So, with Big Data you have, well… a lot of data. Therefore you need a very fast way to push data forward, buffer data (you cannot process a lot of data synchronously efficiently) and consume data.
Streams basically provide you a buffering service so that you can decouple your permanent data stores (sinks) from the original sources. Therefore you don’t have to synchronously process every source event to be stored in your data store. You create a stream which you publish to your data providers — your data providers push data to this stream. Your AWS entities that are able to read streams (e.g. EC2 custom applications, AWS Lambdas, AWS Firehoses… ) read the streams and process the events and/or store the events to permanent data stores (S3, RDS, Redshift, DynamoDB), or you move the events from streams to some other AWS entities (AWS SQS, AWS SNS) or to other AWS streams for further processing.
AWS provides good buffers — streams, queues and topics. We have already covered some AWS idiomatic queue/notification uses for AWS SQS (Simple Queue Service) and AWS SNS (Simple Notification Service). In this chapter we talk only about streams.
AWS Kinesis is a simple way to provide a very fast buffer for many kinds of events. Kinesis actually provides three different services:
- Kinesis Streams — Basic stream service to buffer your data events.
- Kinesis Firehoses — Load your stream data to AWS permanent data stores (S3, Redshift, DynamoDB…).
- Kinesis Analytics — Analyze your data streams using SQL.
Kinesis can buffer your events up to 7 days. Kinesis Streams are elastic as almost all AWS services — they grow and shrink according to your needs — you can easily scale out your streams by adding more shards.
There is also a concept called DynamoDB Streams — you can easily capture events in your DynamoDB tables (inserts/updates…) by pushing these events to a DynamoDB Stream (which can then be consumed by other AWS services…).
2. Storing Big Data Using AWS
We could talk a lot about various possibilities but this blog post is already getting longer than we intended. So let’s make it brief to introduce one AWS Big Data Best Practice: Store it first in S3. Why S3? S3 is extremely durable (ridiculous eleven nines durability) and very cost effective way to store practically unlimited amount of data. Using S3 you can also do something you cannot easily do with SQL/NOSQL data stores: store the data in its original non-processed raw format. Therefore you always have your raw data if something happens to your more processed data stores. From S3 you can read and process your data any way you like with many various AWS services (see next chapter) and store the more processed highly structured data to RDS / Redshift or less stuctured data to DynamoDB (or to some other S3 bucket…).
3. Processing Big Data Using AWS
One issue with Big Data is that even though you could store the Big Data mass in your permanent data storage you may not efficiently process the data mass since your processing entity will be the bottle neck with a lot of data.
Open source community has created some very successful tools for processing and analyzing Big Data masses. One of the tools is called Hadoop. AWS has adopted Hadoop as a service called Elastic Map Reduce (EMR) which can be used to process terabytes or even petabytes of data. The major paradigm with Hadoop / EMR is not to fetch data to the processing entity but to send the processing logic to where the data exists. Another paradigm is to distribute the data set into many overlapping entities called nodes, therefore providing redundancy (if you loose one node — no problem). And once your data is distributed into redundant data entities (nodes), why not send the application logic into the nodes for processing (instead of fetching the data from nodes to the processing unit). This process uses another paradigm which gave name to the AWS Elastic MapReduce service: Map — distribute processing, Reduce — reduce results. The paradigm is the same as the basic primitives found in functional languages like in Clojure (reminder: we need to write a post later regarding this exciting functional language). You send your application logic to a collection (nodes in EMR) and then you reduce (e.g. sum) the results. And the best part: You don’t have to find the hardware for Hadoop cluster — EMR automatically provides the cluster with other AWS services. And it’s elastic of course — you can dynamically scale out and in the cluster size according to your needs. And if you have your master data in S3 (see the best practice mentioned above) you don’t have to worry about the cluster survival — you can just relaunch the cluster in minutes (e.g. would you like the idea of giving your analysts a dashboard to automatically launch EMR cluster for ad hoc analysis on a need basis?)
There is so much more to tell about processing Big Data in AWS, but we just don’t have the space for it in this blog post — e.g OSS tools you can use processing Big Data in AWS (e.g. Hive, Pig, Spark…), off-the-self packaged Big Data EC2 images in AWS Marketplace etc. So, we tried to keep this chapter as a short introduction to the most important AWS Big Data service — EMR.
BTW. Amazon Web Services provides so called spot instances which are perfect for EMR since you survive a node going down (you can bid instances e.g. -50% from list EC2 prices).
4. Visualizing Big Data using AWS
AWS provides one excellent tool to visualize Big Data: Amazon QuickSight. We didn’t have that much time to explore QuickSight so let’s write another blog post about it later. AWS also provides CloudWatch monitoring views which can be used to visualize e.g. Kinesis Streams. And then there are quite a few of commercial visualization tools which you can buy in AWS Marketplace (Tableau, Spotfire…), and various OSS visualization tools (consult the book of knowledge — Google).
Conclusion
AWS is a one-stop-shop to stream, store, process and visualize your Big Data — go no further.
Both writers are AWS Certified Solutions Architects Associate, architecting and implementing AWS projects in Tieto CEM Finland. If you are interested about starting a new AWS project in Finland, you can contact us with firstname.lastname at tieto.com.
Kari Marttila & Timo Tapanainen
Kari Marttila’s Home Page in LinkedIn: https://www.linkedin.com/in/karimarttila/
Timo Tapanainen’s Home Page in LinkedIn: https://www.linkedin.com/in/timo-tapanainen/